Cybersecurity Research #
In the spring semester of my freshman year, I worked on a cybersecurity research project under Professor Dmitry Evtyushkin. The following is a report I wrote at the end of the semester describing what I had accomplished.
End of Semester Independent Study Report #
Philip Roberts #
5/18/2023 #
During the spring semester of 2023, I participated in an independent study under Professor Dmitry Evtyushkin. I worked on a research project alongside PhD student Tim Lesch. The goal of this research project is to study cybersecurity vulnerabilities involving graphics processing unit (GPU) contention. A program is executed to initiate usage of the internal GPU in a central processing unit (CPU), which increases the latency of communication between CPU cores. Two separate processes running on different CPU cores communicate with each other to measure this latency. Based on the latency of the signals between the two CPU cores, the research group postulates that an unsupervised process on the computer may be able to determine the activities of the user. This kind of attack has the potential to record the keystrokes and web browsing activity of the user of the computer.
My role in this project, this semester, has been to research and apply supervised machine learning (ML) techniques to labeled latency data. In the first half of the semester, I worked on developing a dense neural network to classify basic latency data. This latency data was not complex, only containing two clearly delineated modes, representing GPU activity and GPU inactivity. I experimented with manipulating input sample length, randomizing the sample data, adding convolutional layers, and decreasing the size of the network. Through these techniques, I was able to improve the accuracy of the model. I automated the testing of neural networks of different sizes using bash shell scripting on a desktop computer running headless Ubuntu Linux.
Next, I explored applying ML techniques other than deep learning to the problem. First, I tested the State Vector Machine (SVM) implementation in scikit-learn, a popular machine learning library for the Python programming language. The SVM was ~99% accurate, a slight improvement over the neural network. After testing the SVM, I used a tool called LazyPredict to test twenty-seven different data classification models. The majority of the models had an unexpected level of accuracy. Because many different models trained easily on the data, we conjectured that less complex pattern analysis may also apply to the classification task. I attempted manual data analysis and classification. I used a technique to take the average of segments of the data, creating a basic data analysis program with perfect accuracy.
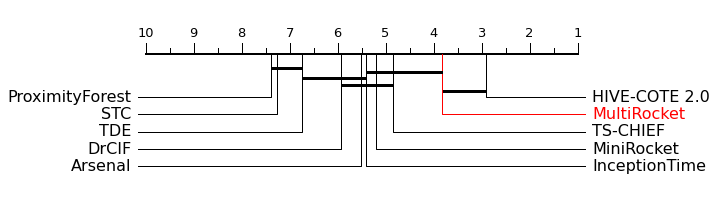
Having implemented several accurate solutions to the basic latency data classification problem, I moved on to research current state-of-the-art (SOTA) solutions for time-series classification (TSC). To document the research process, I wrote a literature review exploring TSC solutions used by other papers for similar tasks, for example, web page fingerprinting. One of the specific needs for the solution was that it would be able to accurately process long time-series data, specifically samples with fifty-thousand points. Initially, I found that most of the SOTA solutions for TSC maximize their input sample length at one thousand data points. In my literature review, I concluded that the Multirocket transform would be the best method for feature extraction due to its linear time performance and high accuracy compared to other SOTA TSC methods. The Multirocket transform is used primarily for feature extraction. It is typically paired with a linear classifier or ridge regression classifier. The Multirocket transform is based on the ROCKET transform (Random Convolutional Kernel Transform), which applies a range of widely varying convolutional kernels to the input data. Multirocket may be a solution to our TSC task, because its range and variety of convolutional kernels may be able to extract features from a very large input sample better than other models. Another TSC model I evaluated was the InceptionTime architecture, which is currently one of the best non-ensemble SOTA models.
Ultimately, the final models chosen to use for CPU latency data classification were a basic convolutional network, Multirocket paired with a linear or ridge regression classifier, and the InceptionTime architecture. In order to further evaluate how well the models scale with increasing data sample lengths, I wrote a comparative performance analysis of the ROCKET transform, transforms based on ROCKET, and InceptionTime. Out of all SOTA TSC methods, MiniRocket, a variant of ROCKET, has the fastest training time and MultiRocket has the second fastest training time. MiniRocket, which Multirocket is based on, was able to train on a dataset with very large samples (sixty-five thousand points) in under a minute. InceptionTime was able to train on a dataset with medium-sized samples (twenty-eight hundred points) in under eight minutes.
Having decided to use the MultiRocket and InceptionTime models, I explored different implementations of these models in popular ML libraries. I successfully tested Multirocket on CPU latency data using sktime, a framework for TSC tasks utilizing ML techniques. While sktime had documentation for their implementation of InceptionTime, I was not able to use its implementation due to a bug. I communicated with the developers of sktime and helped to test their implementation of InceptionTime, and was able to apply it to CPU latency data.
Over the course of this semester, I implemented several ML techniques to create highly accurate classifiers for CPU latency data. Then, I researched SOTA TSC methods to find deep learning models potentially capable of classifying more complex CPU latency data for keylogging or web page fingerprinting. Lastly, I implemented these models with basic CPU latency data and created instantiations of the models with high accuracy. The next step in this research is to create a dataset of more complex CPU latency data, then train the selected models on this dataset.
Literature Review of Current SOTA Deep Learning Models for Time Series Classification tasks #
 (
({kind=link}
Purpose
In this literature review I evaluate different neural network architectures for time series classification (TSC) focusing on the size of the input samples.
Models used for website fingerprinting
In LockedDown: Exploiting Contention on Host-GPU PCIe Bus for Fun and Profit, a fully convolutional neural network is applied in two case studies, a covert channel attack and a web page fingerprinting attack. The model used by the paper is the TSC network used as an example in the Keras documentation. This network has an input layer of 500 samples, which may serve as our baseline.
Website Fingerprinting Through the Cache Occupancy Channel and its Real World Practicality compared the accuracy of convolutional neural networks (CNNs) and long short-term memory (LSTM) networks for website fingerprinting. LSTM was slightly more accurate than the CNN model for website fingerprinting. The LSTM model used in this paper was originally used by Automated Website Fingerprinting through Deep Learning, which compared the SDAE, CNN, and LSTM models for accuracy of time series classification of network packets. This paper also found that the LSTM model was the most accurate. This LSTM model has an input layer of 1000 samples.
MINIROCKET and Scalability
Finally, MINIROCKET was introduced in 2020, which is up to 75 times faster than it’s predecessor, ROCKET. ROCKET uses 10,000 random convolutional kernels to extract features from an input data sample. Each kernel produces two features, so both MINIROCKET and ROCKET produce 20,000 features from an input sample. MINIROCKET also uses 10,000 convolutional kernels, but does not select them randomly. MINIROCKET makes changes to ROCKET to remove almost all randomness from convolutional kernel selection by fixing the weights, bias, dilation, and padding of the kernels. MINIROCKET was used to train and test all of 109 datasets from the UCR archive in under ten minutes, achieving state-of-the-art accuracy.
According to the MINIROCKET paper, while the accuracy of the most accurate current TSC solutions has improved, computational complexity and a lack of scalability remain persistent problems. InceptionTime is one of the models in the list of current most accurate TSC solutions.
Both MINIROCKET and ROCKET solve the scalability problem because they are linear in the number of kernels and features. That is, the performance of MINIROCKET is O(k · n · l), where k is the number of kernels, n is the number of examples, and l is the length of the time series.
In the MINIROCKET paper, MINIROCKET and other models were trained using a single CPU core. MINIROCKET took eight minutes to be trained on all 109 datasets from the UCR archive, while InceptionTime took more than 4 days to be trained.
Classifiers used with ROCKET Classifiers
MINIROCKET is useful for feature extraction, which then can be used in conjunction with a classifier. The original MINIROCKET paper utilizes a linear classifier to achieve high accuracy, but this is not the only option. In An Exploration of ARM System-Level Cache and GPU Side Channels, the MINIROCKET transform is tested for accuracy with a ridge regression classifier and a one-dimensional CNN, in two different scenarios. The two models are used to classify data from the shared cache or the GPU of an ARM SoC. In the closed world case, the victim of the attack only visits websites from a list of identified sensitive websites. In the open world case, the victim also visits websites outside of the list. In the closed world case, the ridge regression classifier demonstrated higher accuracy, while in the open world case, the 1-D CNN demonstrated higher accuracy. Using these models, the paper showed that a cache occupancy side channel can be constructed to reliably fingerprint user website activities.
MultiRocket
In 2022, the researchers that originally created ROCKET and MINIROCKET created MultiRocket, which improves upon the accuracy of MINIROCKET by adding multiple pooling operators and transformations, which improves the diversity of the features generated. MultiRocket takes the first order difference of the input time series, and convolves it with a different set of kernels because the first order difference is shorter by 1. MultiRocket generates roughly 50,000 features per time series, compared to MINIROCKET’s 20,000.
Conclusion
Because of it’s scalability and accuracy, MultiRocket is the best choice for a time series classification task with large input samples.